Accurate Data Discovery: Spirion’s Sensitive Data Platform
Comply with privacy regulations, avoid costly fees, protect against data breaches, and defend your organization’s reputation.


Discover Sensitive Data Anywhere:
Uncover structured or unstructured data with 98.5% accuracy, eliminating false positives to save you time.

Improve Data Security:
Optimize costs by focusing resources on critical data, avoiding waste while minimizing data footprints.

Reduce Data Storage Costs:
Minimize data storage costs through effective remediation, paying only for essential storage space.
Performance & Scalability
Cloud-First Security
Designed for zero trust and hybrid work, the platform’s flexible approach to data discovery and classification supports at scale data locations like databases, data lakes, file types, and cloud repositories such as Amazon S3 Buckets.
Performance & Scalability
Comprehensive File Coverage
Enjoy wide coverage across structured and unstructured data file types including Microsoft Office, PDFs, images, text, personal storage files, and more and apply the necessary controls.
Performance & Scalability
Efficient & Affordable Scalability
Harness dynamic Discovery Teams of agents to scale up scanning speeds and flexible extensions and integrations in the Spirion Marketplace, and Microsoft Azure Marketplace.
Performance & Scalability
Optimized Bandwidth
Keep scanning close to data sources to reduce bandwidth requirements. Avoid contention and ensure high-speed scanning, optimizing performance during extensive data discovery.
Key Features

Progress Tracking:
Tangible metrics track progress, demonstrating ROI and supporting business cases for new initiatives.

Data Asset Inventory (DAI):
Catalog data assets, map flow, and track assets that contain sensitive data and assign owners, descriptions, physical locations, and security postures.

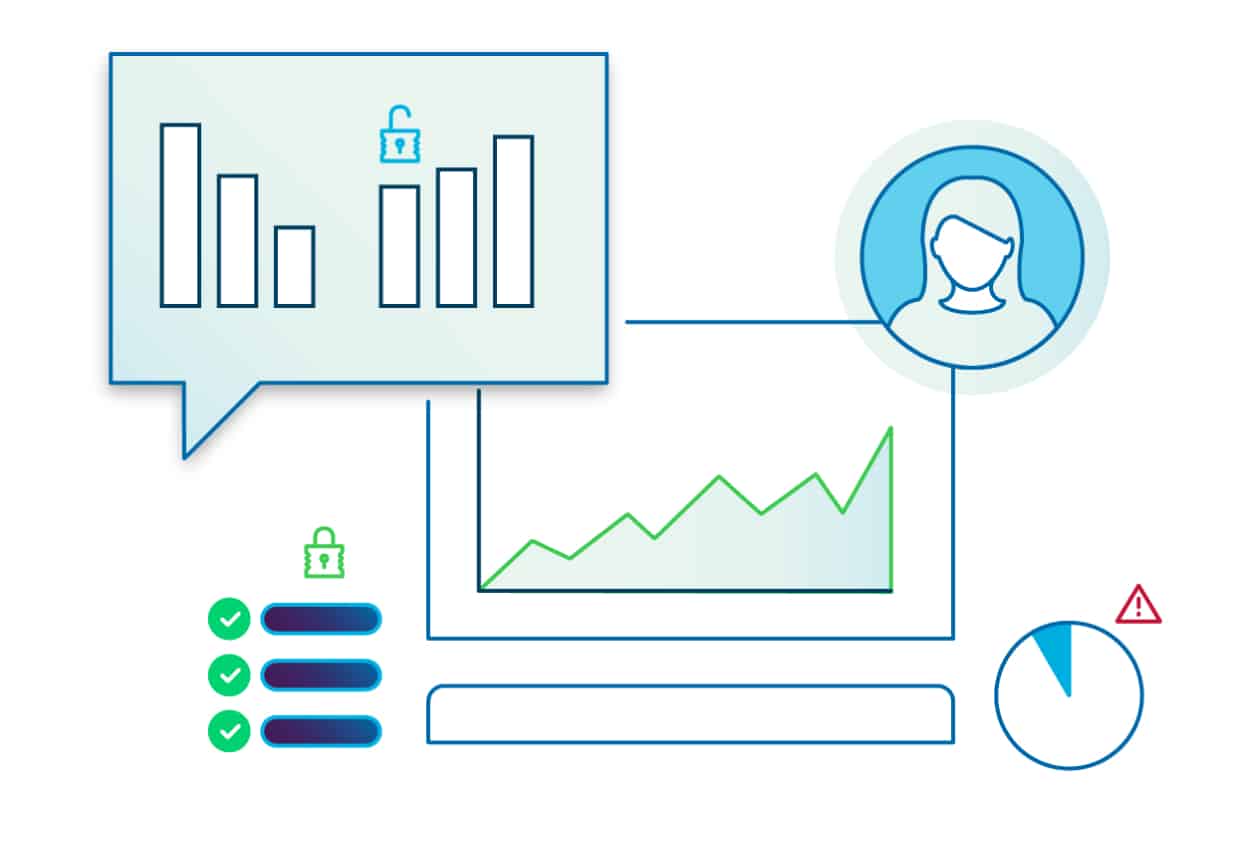
SDV3™ Sensitive Data Risk Dashboard:
Measure of risk helps you focus on what matters most — spotlighting the riskiest data assets to objectively manage trade-offs and quantify your success.

SPIglass™ Executive Dashboard:
Presents sensitive data risk scoring in financial terms that are meaningful to board members, executive leadership, and other stakeholders.

Custom Reports:
Visual, in-app interface to create shared report libraries, custom tailored to user’s information needs – no SQL queries or APIs needed.

Spirion Enhanced Analytics (SEA):
Analyze vast volumes of petabytes of data from your own BI tools with a powerful, no-code solution to easily build your own data models and visualizations.

Sensitive Data Finder:
Extend identity-centric discovery for automated responses to complex SRR/IRR/DSAR requests. Increase response speeds, eliminate human error, and minimize risk.

Sensitive Data Watcher®:
Monitor unusual or aberrant behavior for User and Entity Behavioral Analytics (UEBA) and incident detection, enhancing overall security.

Massive Parallel Scans:
Allocate resources to consistently scale your analysis and understand, classify, and remediate the largest data stores.
Check out our Solution Overview
Spirion Sensitive Data Platform (SDP) provides Privacy-Grade™ data discovery and purposeful classification in a highly scalable SaaS hybrid architecture.