Sensitive data discovery tools
- What is sensitive data discovery?
- Benefits of sensitive data discovery
- Semantic data discovery
- How do you identify sensitive data?
- Where can sensitive data be found?
- Industries where sensitive data discovery is important
- How sensitive data discovery fits into Data Lifecycle Management (DLM)
- Sensitive data discovery solutions
- Why choose Spirion sensitive data discovery tools
Today’s business climate is more data-driven than ever before. Organizations are constantly creating, storing, and managing data that could be classified as sensitive information. Your team may think they know where all personal and sensitive information lives in your organization, but more often than not, security teams discover dark data hidden in unexpected places. If your team isn’t aware of all your collected data that exists, how can they confidently protect and mitigate risk for your organization? Awareness is essential, but it’s a tall order in today’s digital landscape. With the rapid adoption of cloud storage, the rise of remote work, and the increasing risk of data breaches, sensitive data can travel through a greater number of paths and can live in an even greater number of locations, many of which are off business premises. This is why sensitive data discovery is integral to creating and maintaining an effective data security plan. While the thought may seem overwhelming at first, Sensitive Data Discovery makes data security management easier for your business. Here, we cover essential guidelines for handling sensitive data and explain how an automated Sensitive data discovery tool can eliminate the risks of data breaches and noncompliance, as well as other headaches for your organization’s security team.
What is sensitive data discovery?
Sensitive data discovery is the process of identifying and locating sensitive data to protect or securely remove any pieces of compromising information. This is a crucial step for security teams to ensure compliance with regulations, to maintain the privacy of their organizations’ customers and employees, and to prevent data breaches and leaks. Since new data is being created on a daily basis, data discovery is an ongoing endeavor that security professionals must proactively work to build a strong, secure foundation.
Benefits of sensitive data discovery
What does your team get out of this sensitive data discovery effort? For one, this process helps your business uphold legal compliance of data protection laws, like the General Data Protection Regulation (GDPR), Health Insurance Portability and Accountability Act (HIPAA), California Privacy Rights Act (CPRA) and New York’s Stop Hacks and Improve Electronic Data Security Act (SHIELD Act). Noncompliance could potentially cost your organization hundreds of thousands of dollars or more depending on the magnitude of a data leak or breach. In addition to compliance with privacy laws, these are other benefits that organizations see after sensitive data discovery:
- Reputation Management: Data breaches or public exposure of sensitive data doesn’t just have a legal or financial effect on your business. It could also damage your organization’s reputability.
- Decrease in Data Storage Spend: With sensitive data discovery, your team can be agile about consolidating where sensitive data needs to live. In addition to less risk, less overall data also means a lowered total cost of data storage and archiving.
- Reduced Sensitive Data Footprint: More isn’t always better, particularly in the case of sensitive data. A reduced sensitive data footprint translates into your organization being more at ease and your security team being enabled to improve data security spend.
Semantic data discovery
As organizations collect and store increasing amounts of data, it becomes more important to have a complete picture of what information is held and where. However, much of this information is easily overlooked when relying on manual or partially automated data classification. In order to provide a more in-depth look into organizational data, semantic data discovery uses advanced algorithms and machine learning to automate classification and analysis. This allows for faster and more accurate data discovery and analysis, allowing an organization to fully leverage information that may have been previously overlooked or underutilized.
How do you identify sensitive data?
The GDPR classes data under two sets: personal data and personal sensitive data. The GDPR considers any publicly available information that can be used to identify a person, like an individual’s name or email address, to be personal data. Sensitive personal data, on the other hand, is a separate category that must be treated with extra security. This includes any data that pertains to information involving racial or ethnic origin, political opinions, religious or philosophical beliefs, trade union membership, genetic data, biometric data, data concerning health, or data concerning a natural person’s sex life or sexual orientation. At a glance, it may seem like most businesses do not need to collect sensitive personal data from their employees or customers. However, even if a business tries to limit the amount of sensitive data they collect, it is likely that data from at least one of the categories above must be gathered for an organization to properly function and ensure the safety of their employees. For example, allergy information or medical issues both fall under the health category of sensitive personal data. Also, if an organization uses biometric authentication for any systems, like fingerprint scanning for employee building entry, that data needs to be protected.
Sensitive data classification levels
Every piece of data has its own unique set of risks, challenges and procedures. By grouping these different pieces of data into classification levels, IT teams can quickly scan and assess how to handle all of the information they have at hand. Each organization may use their own classification terminology, but generally, sensitive data classification falls under these four classes:
- Public: Information that is freely available and accessible to the public, such as contact information, marketing materials, or consumer pricing.
- Internal: Data that is not meant for public disclosure and has low security requirements, like sales playbooks or company organizational charts.
- Confidential: Sensitive data that if compromised could negatively impact the organization, like employee salaries or vendor contracts
- Restricted: Highly sensitive corporate data that if compromised could put the organization at financial, legal, regulatory, or reputational risk. This could be information like customers’ PII or credit card information.
Examples of sensitive data
Sensitive data comes in all forms, shapes and sizes. Some have greater legal protections than others and you may notice them referenced repeatedly in legal data protection guidelines. Below are five examples of sensitive data your organization should be on top of.
Protected Health Information (PHI)
Although PHI is most commonly associated with the healthcare industry, organizations outside of the medical scope are likely to have collected and stored PHI from their employees or customers. PHI can include a person’s medical conditions, disabilities, medical history, names of relatives and medical emergency contact information. Common examples of PHI that most employers have stored in their network are allergy information or emergency contact information from their staff.
Payment Card Industry Data Security Standard (PCI DSS)
PCI DSS ensures that companies process, store, and transmit credit card information safely and securely. Under these requirements, any company handling a person’s credit card data must adequately protect that information. This includes any type of cardholder data, including Primary Account Numbers, cardholder name, service code, card expiration date, magnetic stripe data, card verification code, and authentication data like PINs.
Biometric data
Biometric information is a recent type of sensitive data that is protected under the CPRA and New York SHIELD Act. Biometrics are physical and behavioral characteristics that can be used to digitally identify a person to grant access to systems, programs, or devices. Some of the most commonly used forms of biometric data include fingerprints, facial recognition, retina scans, and voice recognition. Biometrics are quickly becoming more common among business offices. A recent study on biometrics in the workplace found that 62 percent of organizations use biometric authentication in some form, and global spending on identity and access management (IAM) solutions is expected to rise from $16 billion in 2022 to $26 billion by 2027. A couple of typical instances where you may see biometrics in the workplace are fingerprint scans to access laptops, entrance requests for restricted areas of a building, or for clocking in and out on time clocks. Other forms of biometrics that are on the leading-edge fall under behavioral characteristics, including typing patterns, physical movements, digital navigation patterns, and digital engagement patterns. Humans generally have a particular cadence and way of interacting with technology, and these measures of data can help identify whether an action made on a device was by a robot or by a human. As technology improves, these types of biometric data may go beyond differentiating between humans and robots, and may be used to differentiate particular individuals.
Consumer behavior data
Another recent type of sensitive data protected by the CPRA, consumer behavior data, pertains to personal information that could be used to identify, relate to, or be linked with a person or their household. This includes records of products purchased, internet browsing history, search history, geolocation data, and any information regarding a consumer’s interaction with an internet website, application, or advertisement. California residents are legally entitled to their consumer behavioral data being protected, since all of these pieces of information can be used to create a profile and potentially identify an individual.
Where can sensitive data be found?
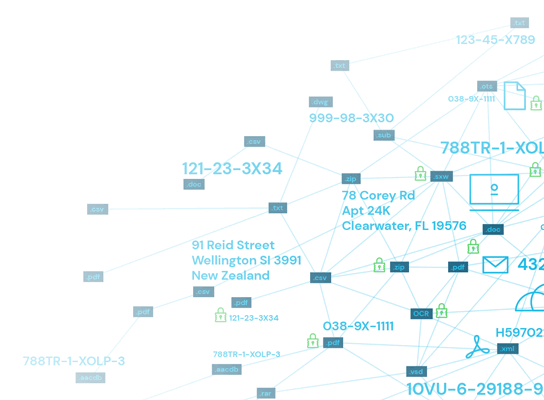
Nowadays, there are many paths that sensitive data can travel, especially with adoption of the cloud. Many organizations reap the benefits of enhanced team collaboration and communication with cloud storage tools, like Google Drive, Dropbox, Microsoft OneDrive, or Amazon Cloud Drive. Organizations may also store information on their own cloud network servers. In Rightscale’s study on IT governance, 81 percent of enterprises were reported to have a multi-cloud strategy in place, with data to support that the number will only continue rising. Other areas where sensitive data can be found include online databases, local network servers, and physical devices. These devices include USB drives, laptops and desktops, smartphones, and desktop phones. If your employees regularly travel outside of the office or work remotely with devices or files that may contain sensitive data, it is important to be aware of this and create a “culture of security” by properly training and giving security guidance to employees. Sensitive data may also be found on digital files, like Excel spreadsheets, PDF documents, or image files.
Structured vs. unstructured data
When trying to discover sensitive data, there are two primary categories of data that determine how easy or difficult that particular piece of information can be located: structured and unstructured data. Structured data, as the name suggests, is data that is coded and organized based on a specific format. This type of data often comes in the form of an Excel spreadsheet or table and is easily searchable for information retrieval. Structured data usually contains quantitative information like business transactions, inventory reports, and financial reports. Since this type of data is usually organized into some type of chart, computers can easily scan, collect, and analyze structured data. On the other side is unstructured data, which isn’t as easily scannable or interpretable by computers. Unstructured data accounts for the majority of the data that organizations create and consume, which is estimated to make up 80-90 percent of the digital universe. Some examples of unstructured data are audio recordings, images, videos, email, and text messages, webpages, blog posts, presentation slide decks, and social media content. All of these types of data do not follow a specific, consistent format, which means they are not as readily searchable. Understanding the differences between these types of data, and the overwhelming amount of unstructured data that is out there, is fundamental to fully appreciating the sensitive data discovery process, and finding the best data discovery tools to help your organization. Data can live in a wide array of places, and not always where you expect it to be. With the majority of difficult-to-search, unstructured data drifting from cloud storage servers to USB drives to email exchanges, this is where sensitive data discovery is a necessary step to any organization’s data security foundation. While you are searching for sensitive data discovery software to aid your security and IT team, be sure to confirm whether those tools are scalable to your needs and have the ability to search for and identify both structured and unstructured sensitive data.
Industries where sensitive data discovery is important
Properly securing and protecting sensitive data is essential for any organization, but certain industries are held to higher standards and are more heavily audited. Some may also have industry-specific rules and regulations they need to adhere to.
- Healthcare: Healthcare organizations handle substantial amounts of patient data on a daily basis, and must comply with HIPAA, HITECH and other data security laws and regulations.
- Financial: Banks, credit unions, investment firms and other types of financial service institutions handle and store sensitive data, like financial records and credit or debit card information, that is heavily regulated.
- Higher Education: Academic campuses store a diverse mix of sensitive data — anywhere from PHI within on-campus clinics to financial data in administrative offices.
- eCommerce: eCommerce organizations carry the great responsibility of protecting sensitive consumer data, especially now with new regulations governed by CPRA.
- Manufacturing: Now with more manufacturing processes being automated and with the adoption of the Internet of Things (IoT), understanding where sensitive data lives and how to protect it is crucial, especially on large-scale industrial projects.
- Telecommunications: Sensitive data like location, transactional data, call recordings and more are constantly collected by telecommunication companies in real-time and must comply with multiple security regulations.
- Government: From local to federal, government organizations collect a tremendous amount of personal data from citizens. While some may be on public record, there are many forms of data, like tax returns, that must be protected.
How sensitive data discovery fits into Data Lifecycle Management (DLM)
Data Lifecycle Management is the process and flow of data, starting from when it’s first created all the way until it is eventually destroyed. Generally, there are six steps to data lifecycle management:
- Creation
- Storage
- Utilization
- Sharing
- Archiving
- Destruction
Sensitive data discovery plays a large role in a few of these steps. For one, any forms of stored data need to be discoverable by an organization’s security team. If a security team is unaware that the data exists, they are unable to have an up-to-date inventory on sensitive data, properly classify sensitive data, report on it, or take data remediation actions. By deploying an automated data discovery process, your team can accurately track where data is being stored, how it’s being used and shared, and ensure that sensitive data is permanently destroyed when needed.
Sensitive data discovery solutions
Effective sensitive data discovery software should utilize the most current technologies, be easy to use, and have the capacity to be customized for your business. With the tremendous amount of sensitive, unstructured data inevitably drifting through your organization, you need to be assured that the tools you use for sensitive data discovery are on the cutting-edge with the ability to accurately locate and remediate data no matter the type or location. The tool or solution you choose should have integrated contextual search intelligence, which grants data mining tools with the ability to analyze complex unstructured data and extract relevant, sensitive information from that analysis. If the tool you are considering utilizes outdated Enterprise Search, it likely doesn’t have the capacity to locate hard-to-find sensitive data. Another factor to consider is how intuitive and user-friendly the tool is. Nothing is worse than your security team pouring wasted hours trying to understand a software that was intended to make their job easier. Tools that have a graphical user interface and visual reporting tend to be more well-received. Additionally, a sensitive data discovery solution should have customization functionality so you can assign classification terms and action triggers that align with your team’s goals and workflows.
Why choose Spirion sensitive data discovery tools
Automated data discovery is the critical first step in any effective information security program — because as we know, you cannot protect sensitive data if you don’t know it exists. Spirion’s data discovery tools perform fast and accurate searches of structured, semi-structured data and unstructured data in locations where many other solutions cannot. This includes data mining within images, on hosted and on-premise email servers, in databases, and in the cloud.
Accurate data discovery solutions
It all starts with accurate discovery of data sources. Understanding what and where sensitive information is allows you to set appropriate levels of control in your data discovery process. The secret behind Spirion’s highly accurate sensitive data discovery software solution is our AnyFind® technology. Our data mining capabilities incorporate contextual search technology that goes beyond fingerprint and pattern or regex-style searching. AnyFind® locates a wide variety of data sources, such as PCI, PHI, and PII data, anywhere it exists, enabling you to quickly and effectively reduce your sensitive data footprint. Our easy-to-use, data discovery platform interface helps quickly perform data classification by setting rules based on sensitivity. From there, remediation is automatically performed based on your data security workflow process. Results are presented in intuitive reports and dashboards, allowing you a visual analysis of insights and patterns.
Find unique sensitive data anywhere with data visualization tools
Building on our industry-leading AnyFind technology, Sensitive Data Engine™ takes finding discrete groups of data — like PHI, PCI, and PII data — to the next level, and it does so with the highest accuracy in the industry. With Spirion’s Sensitive Data Engine, you can use an intuitive GUI to build sensitive data definitions, allowing you to define the criteria to locate proprietary and unique organizational data. Data that can only be identified by its creator or owner can pose one of the greatest challenges in your data loss prevention strategy.
Search for sensitive data everywhere
Sensitive information often turns up in unexpected places. It can be in databases, Excel spreadsheets, or PDF documents. It might even be in images. Spirion’s automated data discovery tools enable you to search everywhere, including within Windows, Mac OS X, Linux, email servers, images, cloud storage, and websites. Flexibly scheduled searches increase the speed of results and can be run in background mode, so they don’t interfere with your day-to-day work. Reaching deep within your organization, our software rapidly creates a global inventory of all sensitive information so you can classify data, report on it, and take data remediation actions — all from a centralized console.
Continuously monitor in real time
Data is constantly being modified and shared, necessitating a strategy that monitors data stores for new instances of sensitive information. Sensitive Data Watcher™ provides always-on monitoring to control data in near-real time across the data security lifecycle. When a file is created, copied, detached from an email, extracted from an archive, retrieved from cloud storage, or otherwise modified, it is instantly searched, automatically classified, and reported upon. Notification, assignment, and data remediation can be performed automatically or manually according to your workflow process. Through continuous monitoring, you can maintain compliance in a world of constant change and stay a step ahead of the auditors.